
日本人の高精度全ゲノムデータの統合的な解析に成功
8月24日 東北大学 プレスリリース
 先日のキャンパスツアーで訪問した東北大学東北メディカル・メガバンク機構のゲノム解析部門を中心とした研究チームは、東北メディカル・メガバンク計画のコホート調査に参加した健常な日本人1,070人分の全ゲノムを解析し、精度検証を進めることで、日本人の全ゲノムリファレンスパネル(以下、1KJPN)を構築しました。
先日のキャンパスツアーで訪問した東北大学東北メディカル・メガバンク機構のゲノム解析部門を中心とした研究チームは、東北メディカル・メガバンク計画のコホート調査に参加した健常な日本人1,070人分の全ゲノムを解析し、精度検証を進めることで、日本人の全ゲノムリファレンスパネル(以下、1KJPN)を構築しました。
今回、1,070人分のDNA情報を次世代シークエンサーで読み取り、のべ約100兆塩基もの高品質な全ゲノム断片配列情報を解読し、スーパーコンピュータによる情報解析技術と他の手法による実験結果による検証とを組み合わせることで、最終的に信頼度の高い2,120万箇所の一塩基バリアント(single-nucleotide variants:以下 SNVs)を発見しました。これらSNVsのうち1,200万箇所はこれまで国際データベースに報告されていない新規のSNVsでした。
今回の1KJPNでは、SNVs同定対象の常染色体領域上の日本人がもつアレル頻度0.1%以上のSNVsをほぼ(90%以上)網羅できていることがスーパーコンピュータによる集団遺伝学のモデルを用いたシミュレーションにより確かめられています。
研究チームは、SNVsに加え、日本人がもつ340万箇所の数十塩基以内の挿入及び欠失(うち新規約200万箇所)や、全ゲノム中の2万個以上の遺伝子のほぼすべての領域におけるコピー数変化の詳細プロファイルの作成についても世界で初めて成功しました。
お米の消化の遺伝子の個人差やHLAの詳細などが統合解析からみえてくる
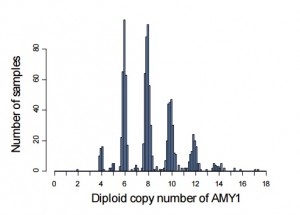
また、お米に含まれるデンプンの消化に関係するアミラーゼ遺伝子(AMY1)が偶数個の単位で個人差があることや、免疫疾患に関連するヒト白血球型抗原(HLA)遺伝子の詳細プロファイルなどの作成などにも成功しました。
この一連の研究で発見された情報は、日本人に固有な体質・疾患の関連遺伝子を大規模に探索研究するための基盤情報であり、日本人の個別化予防・医療研究を加速する重要な成果です。本研究成果は、2015年8月21日に英国科学誌「Nature Communications (ネイチャー・コミュニケーションズ)」オンライン版で公開されました。
タグ:SNVs, ゲノム, 東北メディカル・メガバンク機構, 東北大学